
When Entity Framework was made open source (which by the way I think is awesome) I posted a possible improvement to the framework which could improve performance especially in scenarios where a set of rows are inserted into a table. There are several different methods of inserting large amounts of data into SQL.
In this post I’m going to outline each approach to bulk inserts and any issues with the approach and then do a comparison on the actual performance of these different methods.
Appending all of the statements into a single command text
Queries to a SQL server are inherently ordered in nature, we cant insert a new row until the previous one is written as SQL has to lock the table to perform our insert operation. This means that for each row we insert we need to go through a series of steps, each of which takes time.

The more latency on our network the longer the green blocks become. So if these are the steps which we go through for a single insert, what does it look like for multiple inserts.

As you can see we spend a lot of time doing all of the wrapping around the statement and not a lot of time actually inserting rows in SQL.
By appending all of the statements into a single command text what we are essentially doing is bundling all of the separate actions we need to perform in out insert together. This give us something like the following:

As you can see this theoretically makes the query much more efficient.
An example of this is if we put the following into a single commandtext
INSERT INTO [StaticVoid.OrmPerformance.Test].[dbo].[TestEntities]
([TestString], [TestDate], [TestInt])
VALUES ('some gumph','2012-1-1',1)
INSERT INTO [StaticVoid.OrmPerformance.Test].[dbo].[TestEntities]
([TestString], [TestDate], [TestInt])
VALUES ('some gumph 2','2012-1-2',2)
INSERT INTO [StaticVoid.OrmPerformance.Test].[dbo].[TestEntities]
([TestString], [TestDate], [TestInt])
VALUES ('some gumph 3','2012-1-3',3)
Using a multi-row insert statement (Aka Row Constructors)
Like a single command text a multi insert statement has the benefit of reducing the number of round trips to the database. In addition inserting multiple rows with a single statement improves the efficiency of the actual SQL execution as it is executed all in one hit. This means that it only needs to do all the fun stuff that SQL need to do for every query once (like generating query plans, locking tables and other things I don’t really understand). This basically gets us back to:
An example of a multi-row insert statement is the following
INSERT INTO [StaticVoid.OrmPerformance.Test].[dbo].[TestEntities]
([TestString], [TestDate], [TestInt])
VALUES ('some gumph','2012-1-1',1)
,('some gumph 2','2012-1-2',2)
,('some gumph 3','2012-1-3',3)
As you can see this is also a lot less text than the above example so it has an additional benefit of reducing the size of the data which needs to be transmitted (and parsed).
One of the interesting things about multi-row insert statements is that MSSQL actually appears to have some limits on the query itself.
- A maximum of 1000 rows can be inserted with row constructors. This is a hard limit which means you get an exception when exceeding this limit. -When you exceed 1000 values in your statement SQL shifts its optimisations to reduce the size of its query plans, this means that there is a sharp spike in query execution times when this value is exceeded.
NOTE row constructors are only available in SQL 2008 and above.
SQL bulk copy
The very best insert performance for inserting large volumes of data can be attained by using SQL Bulk Copy. This method bypasses the SQL query language entirely and streams data directly to SQL.
While SQL bulk copy is exceptionally fast at inserting large volumes of data there are several downsides to using this method.
- There is no way to get a response back from your write, this means that you cant get back generated IDs for your newly inserted rows.
- There is a set up cost incurred with running SQL bulk copy. This means it is not efficient for small datasets.
How they compare
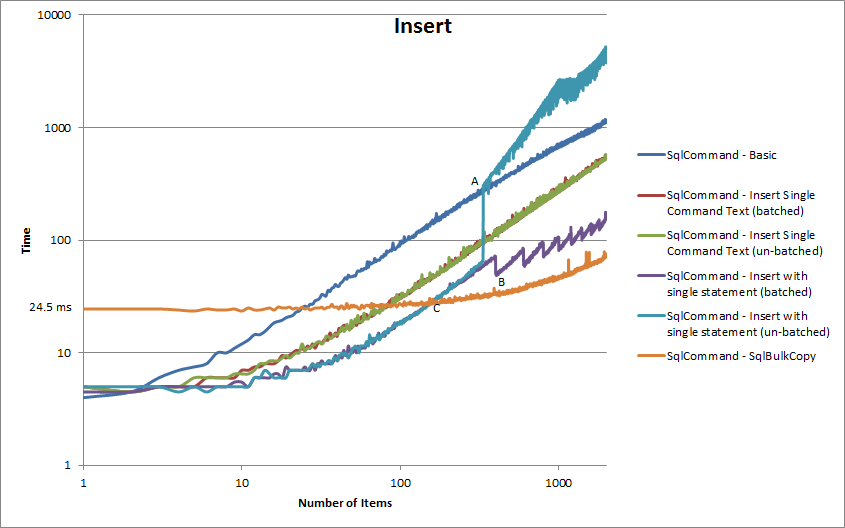
The above graph tells us some interesting things about the way each of these bulk methods work and their individual weaknesses.
At point A we can see a large spike in the execution time for our multi-row insert statement. This occurs at 334 rows inserted. As we discussed earlier SQL changes its behavior when there are more than 1000 in a single statement. In the above case the SQL statement contained 3 values per row. This means that on the 334th row inserted we have 1002 values in our SQL statement and hence SQL begins to optimise for query plan size. For more info on this particular scenario read Martin Smiths answer on Stack Overflow (which is a very good read). Its also interesting to note that in my example after this optimisation change we see multi-row inserts become slower than individual SQL insert statements each submitted separately to the database.
If we look at point B on the graph we can see a series of sudden drops in execution time which occur every 200 rows beginning on the 400th row. This occurs in correlation with beginning a new batch in our batched approach, ie 401 rows in 3 batches takes less time than 400 rows in 2 batches. This is a very interesting result which I need to do more investigation into (if anyone knows any more about this or has a theory I would love to hear about it). My only hypothesis is that the query plan is calculated on the single row insert and then used for the two larger inserts (which have more variables and are hence harder to parse).
With our SQL bulk copy line there are a couple of important points to note. Firstly as you can see there appears to be a set up cost associated with the method of around 25ms. Because of this set up cost SQL bulk copy is significantly slower for small numbers of rows. Secondly the point at which SQL bulk copy becomes more efficient in my example is around 150 rows (point C on the graph).
Detailed times and memory usage results can be found here.
Thanks to Eli Weinstock Herman (t | b) for the bulk copy scenario.